These three links caught my attention as a group and I thought I’d share them here.
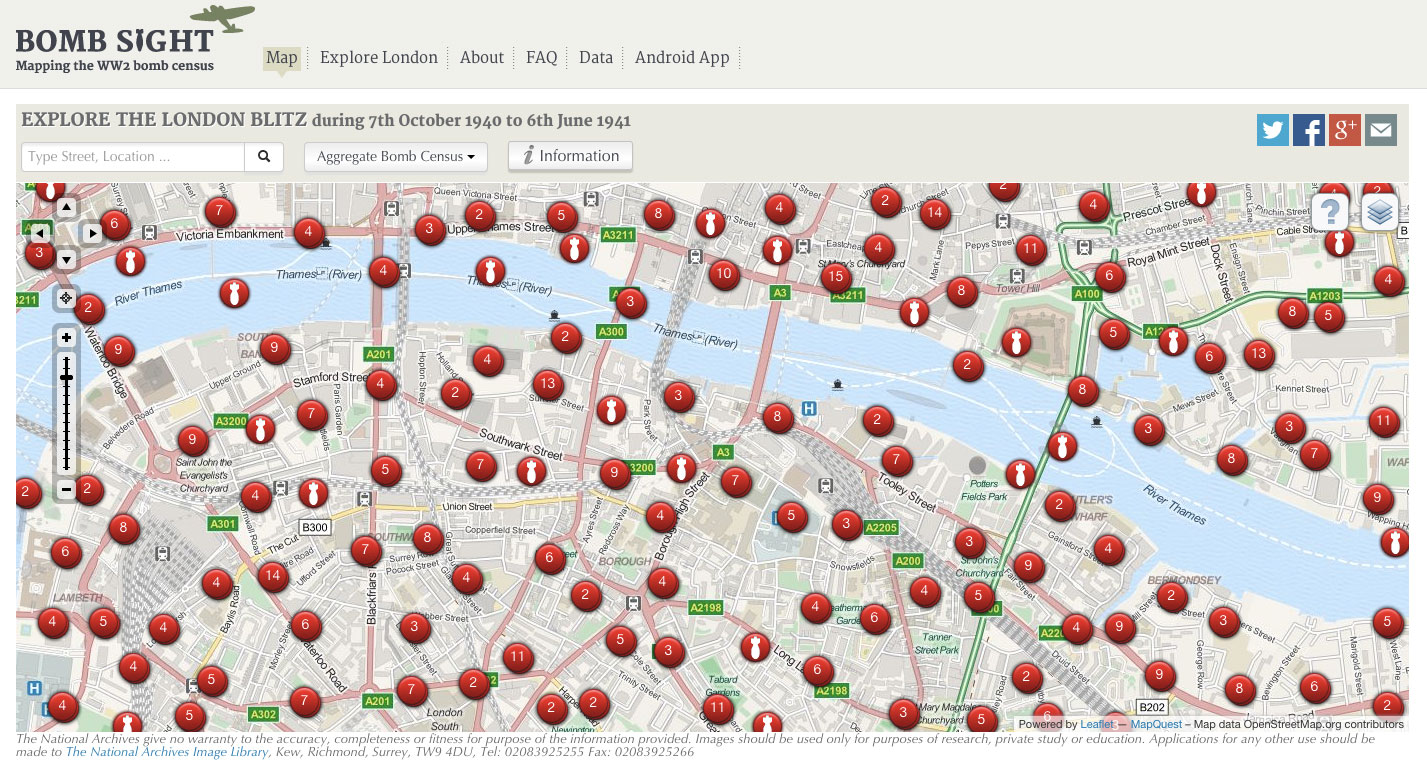
Bomb Sight uses archival data and modern mapping software to display where all the recorded bombs fell on London during WW2. The delivery mechanism means people immediately search for the places and areas that they live, work and inhabit everyday. Being able to relate archival data to your life now is such a powerful way to connect with history and to understand the blitz’s impact.

Starfish sites where created away real bombing targets in the UK to try and draw attention and bombs from German raids.

Wartime factories on the west coast of America created elaborate set designs on top of their factories to disguise them as fields and suburban streets.